kubernetes service 和 kube-proxy详解
kubernetes service 和 kube-proxy详解
service 是Kubernetes里面非常重要的一个功能,用以解决负载均衡、弹性伸缩、升级灰度等等
本文先从概念介绍到实际负载均衡运转过程中追踪每个环节都做哪些处理,同时这些包会相应地怎么流转最终到达目标POD,以阐明service工作原理以及kube-proxy又在这个过程中充当了什么角色。
service 模式
根据创建Service的type类型不同,可分成4种模式:
- ClusterIP: 默认方式。根据是否生成ClusterIP又可分为普通Service和Headless Service两类:
普通Service:通过为Kubernetes的Service分配一个集群内部可访问的固定虚拟IP(Cluster IP),实现集群内的访问。为最常见的方式。Headless Service:该服务不会分配Cluster IP,也不通过kube-proxy做反向代理和负载均衡。而是通过DNS提供稳定的网络ID来访问,DNS会将headless service的后端直接解析为podIP列表。主要供StatefulSet中对应POD的序列用。
NodePort:除了使用Cluster IP之外,还通过将service的port映射到集群内每个节点的相同一个端口,实现通过nodeIP:nodePort从集群外访问服务。NodePort会RR转发给后端的任意一个POD,跟ClusterIP类似LoadBalancer:和nodePort类似,不过除了使用一个Cluster IP和nodePort之外,还会向所使用的公有云申请一个负载均衡器,实现从集群外通过LB访问服务。在公有云提供的 Kubernetes 服务里,都使用了一个叫作 CloudProvider 的转接层,来跟公有云本身的 API 进行对接。所以,在上述 LoadBalancer 类型的 Service 被提交后,Kubernetes 就会调用 CloudProvider 在公有云上为你创建一个负载均衡服务,并且把被代理的 Pod 的 IP 地址配置给负载均衡服务做后端。ExternalName:是 Service 的特例。此模式主要面向运行在集群外部的服务,通过它可以将外部服务映射进k8s集群,且具备k8s内服务的一些特征(如具备namespace等属性),来为集群内部提供服务。此模式要求kube-dns的版本为1.7或以上。这种模式和前三种模式(除headless service)最大的不同是重定向依赖的是dns层次,而不是通过kube-proxy。
service yaml案例:
1 | apiVersion: v1 |
ports 字段指定服务的端口信息:
port:虚拟 ip 要绑定的 port,每个 service 会创建出来一个虚拟 ip,通过访问vip:port就能获取服务的内容。这个 port 可以用户随机选取,因为每个服务都有自己的 vip,也不用担心冲突的情况targetPort:pod 中暴露出来的 port,这是运行的容器中具体暴露出来的端口,一定不能写错–一般用name来代替具体的portprotocol:提供服务的协议类型,可以是TCP或者UDPnodePort: 仅在type为nodePort模式下有用,宿主机暴露端口
nodePort和loadbalancer可以被外部访问,loadbalancer需要一个外部ip,流量走外部ip进出
NodePort向外部暴露了多个宿主机的端口,外部可以部署负载均衡将这些地址配置进去。
默认情况下,服务会rr转发到可用的后端。如果希望保持会话(同一个 client 永远都转发到相同的 pod),可以把 service.spec.sessionAffinity 设置为 ClientIP。
Service和kube-proxy的工作原理
kube-proxy有两种主要的实现(userspace基本没有使用了):
- iptables来做NAT以及负载均衡(默认方案)
- ipvs来做NAT以及负载均衡
Service 是由 kube-proxy 组件通过监听 Pod 的变化事件,在宿主机上维护iptables规则或者ipvs规则。
Kube-proxy 主要监听两个对象,一个是 Service,一个是 Endpoint,监听他们启停。以及通过selector将他们绑定。
IPVS 是专门为LB设计的。它用hash table管理service,对service的增删查找都是*O(1)*的时间复杂度。不过IPVS内核模块没有SNAT功能,因此借用了iptables的SNAT功能。IPVS 针对报文做DNAT后,将连接信息保存在nf_conntrack中,iptables据此接力做SNAT。该模式是目前Kubernetes网络性能最好的选择。但是由于nf_conntrack的复杂性,带来了很大的性能损耗。
iptables 实现负载均衡的工作流程
如果kube-proxy不是用的ipvs模式,那么主要靠iptables来做DNAT和SNAT以及负载均衡
iptables+clusterIP工作流程:
- 集群内访问svc 10.10.35.224:3306 命中 kube-services iptables(两条规则,宿主机、以及pod内)
- iptables 规则:KUBE-SEP-F4QDAAVSZYZMFXZQ 对应到 KUBE-SEP-F4QDAAVSZYZMFXZQ
- KUBE-SEP-F4QDAAVSZYZMFXZQ 指示 DNAT到 宿主机:192.168.0.83:10379(在内核中将包改写了ip port)
- 从svc description中可以看到这个endpoint的地址 192.168.0.83:10379(pod使用Host network)
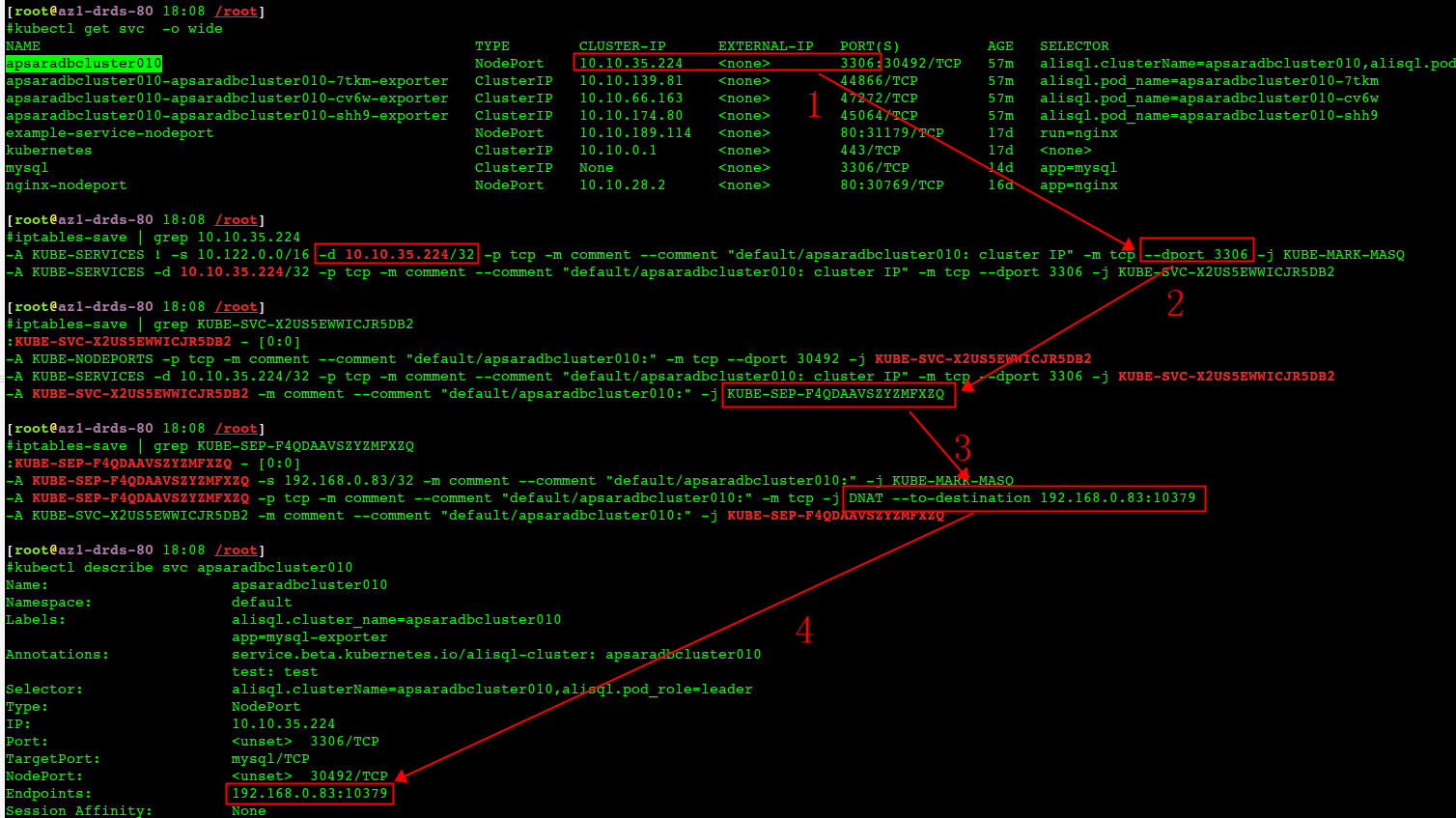
iptables规则解析如下(case不一样,所以看到的端口、ip都不一样):
1 | -t nat -A {PREROUTING, OUTPUT} -m conntrack --ctstate NEW -j KUBE-SERVICES |
在对应的宿主机上可以清楚地看到容器中的mysqld进程正好监听着 10379端口
1 | [root@az1-drds-83 ~]# ss -lntp |grep 10379 |
对应的这个pod的description:
1 | #kubectl describe pod apsaradbcluster010-cv6w |
DNAT 规则的作用,就是在 PREROUTING 检查点之前,也就是在路由之前,将流入 IP 包的目的地址和端口,改成–to-destination 所指定的新的目的地址和端口。可以看到,这个目的地址和端口,正是被代理 Pod 的 IP 地址和端口。
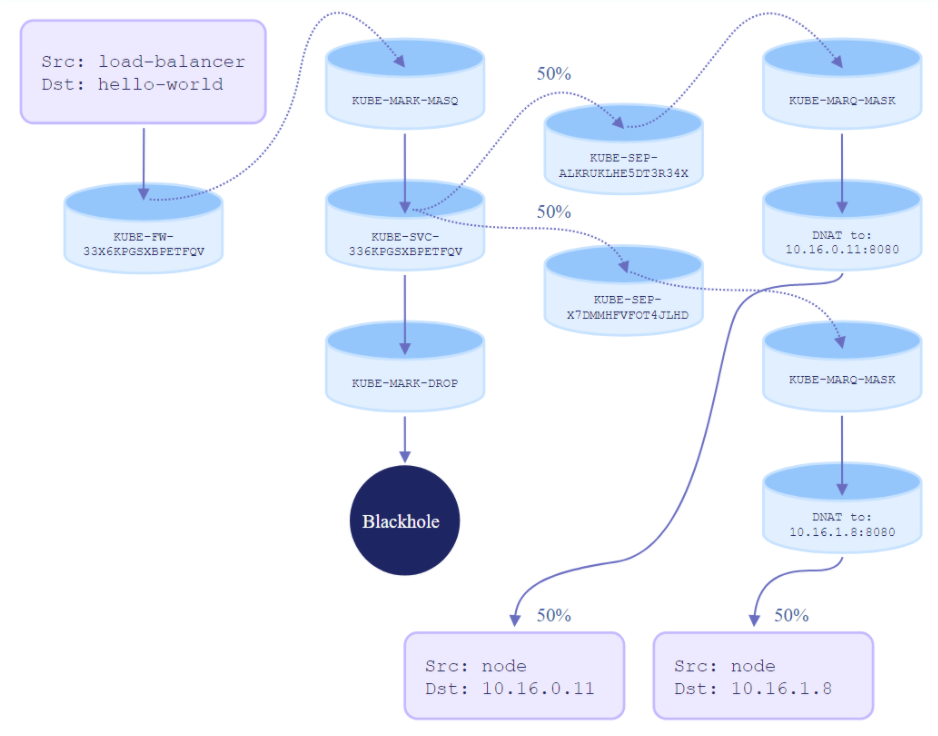
如下是一个iptables来实现service的案例中的iptables流量分配规则:
三个pod,每个pod承担三分之一的流量
1 | iptables-save | grep 3306 |
到这里我们基本可以看到,利用iptables规则,宿主机内核把发到宿主机上的流量按照iptables规则做dnat后发给service后端的pod,同时iptables规则可以配置每个pod的流量大小。再辅助kube-proxy监听pod的起停和健康状态并相应地更新iptables规则,这样整个service实现逻辑就很清晰了。
看起来 service 是个完美的方案,可以解决服务访问的所有问题,但是 service 这个方案(iptables 模式)也有自己的缺点。
首先,如果转发的 pod 不能正常提供服务,它不会自动尝试另一个 pod,当然这个可以通过 readiness probes 来解决。每个 pod 都有一个健康检查的机制,当有 pod 健康状况有问题时,kube-proxy 会删除对应的转发规则。
另外,nodePort 类型的服务也无法添加 TLS 或者更复杂的报文路由机制。因为只做了NAT
ipvs 实现负载均衡的原理
ipvs模式下,kube-proxy会先创建虚拟网卡,kube-ipvs0下面的每个ip都对应着svc的一个clusterIP:
1 | # ip addr |
kube-ipvs0下面绑的这些ip就是在发包的时候让内核知道如果目标ip是这些地址的话,这些地址是自身的所以包不会发出去,而是给INPUT链,这样ipvs内核模块有机会改写包做完NAT后再发走。
ipvs会放置DNAT钩子在INPUT链上,因此必须要让内核识别 VIP 是本机的 IP。这样才会过INPUT 链,要不然就通过OUTPUT链出去了。k8s 通过kube-proxy将service cluster ip 绑定到虚拟网卡kube-ipvs0。
同时在路由表中增加一些ipvs 的路由条目:
1 | # ip route show table local //等于ip route list table local |
而接下来,kube-proxy 就会通过 Linux 的 IPVS 模块,为这个 IP 地址设置三个 IPVS 虚拟主机,并设置这三个虚拟主机之间使用轮询模式 (rr) 来作为负载均衡策略。我们可以通过 ipvsadm 查看到这个设置,如下所示:
1 | ipvsadm -ln |grep 10.68.114.131 -A5 |
172.20.. 是后端真正pod的ip, 10.68.114.131 是cluster-ip.
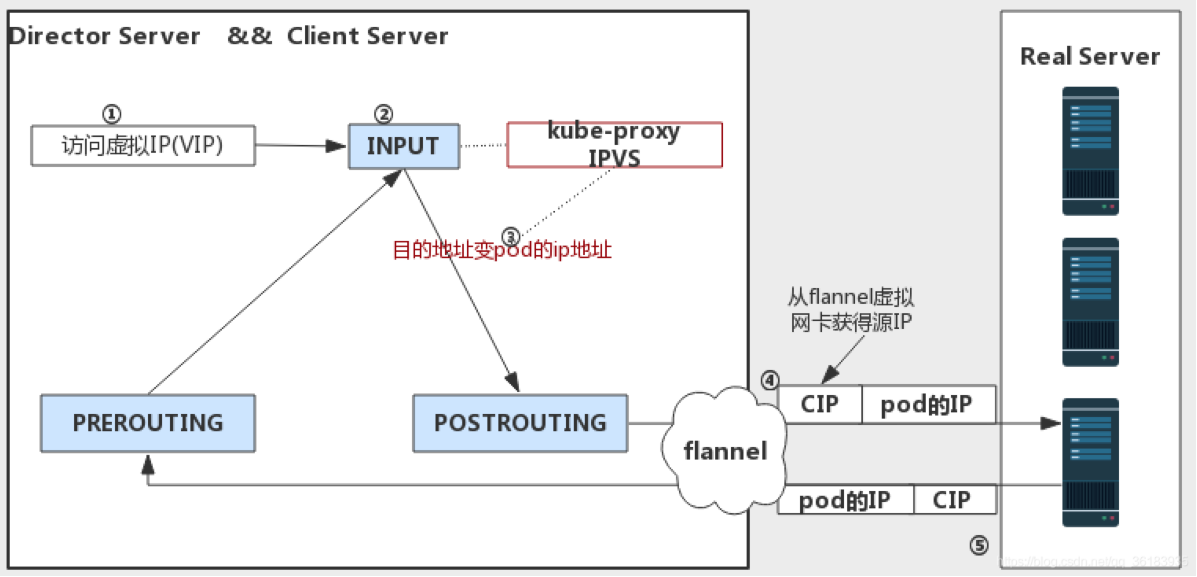
完整的工作流程如下:
- 因为service cluster ip 绑定到虚拟网卡kube-ipvs0上,内核可以识别访问的 VIP 是本机的 IP.
- 数据包到达INPUT链.
- ipvs监听到达input链的数据包,比对数据包请求的服务是为集群服务,修改数据包的目标IP地址为对应pod的IP,然后将数据包发至POSTROUTING链.
- 数据包经过POSTROUTING链选路由后,将数据包通过tunl0网卡(calico网络模型)发送出去。从tunl0虚拟网卡获得源IP.
- 经过tunl0后进行ipip封包,丢到物理网络,路由到目标node(目标pod所在的node)
- 目标node进行ipip解包后给pod对应的网卡
- pod接收到请求之后,构建响应报文,改变源地址和目的地址,返回给客户端。
ipvs实际案例
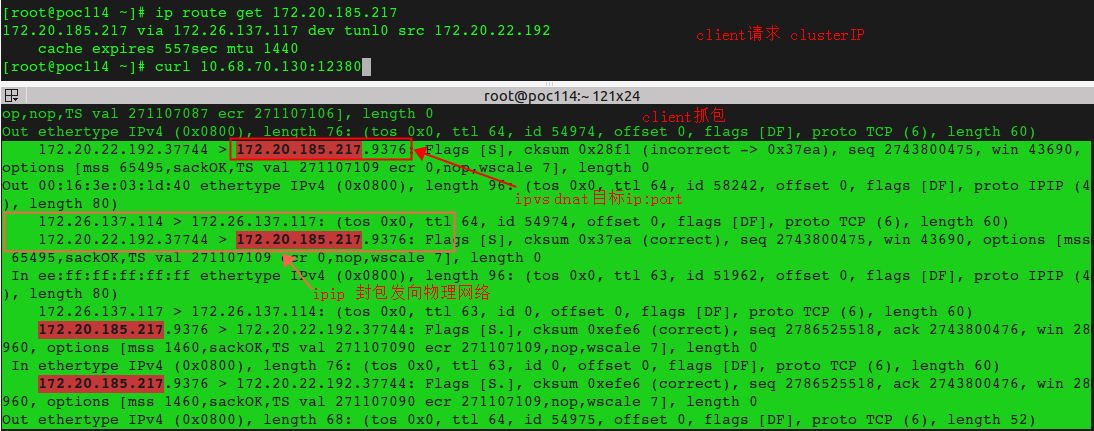
ipvs负载均衡下一次完整的syn握手抓包。
宿主机上访问 curl clusterip+port 后因为这个ip绑定在kube-ipvs0上,本来是应该发出去的包(prerouting)但是内核认为这个包是访问自己,于是给INPUT链,接着被ipvs放置在INPUT中的DNAT钩子勾住,将dest ip根据负载均衡逻辑改成pod-ip,然后将数据包再发至POSTROUTING链。这时因为目标ip是POD-IP了,根据ip route 选择到出口网卡是tunl0。
可以看下内核中的路由规则:
1 | # ip route get 10.68.70.130 |
于是cip变成了tunl0的IP,这个tunl0是ipip模式,于是将这个包打包成ipip,也就是外层sip、dip都是宿主机ip,再将这个包丢入到物理网络
网络收包到达内核后的处理流程如下,核心都是查路由表,出包也会查路由表(判断是否本机内部通信,或者外部通信的话需要选用哪个网卡)
ipvs的一些分析
ipvs是一个内核态的四层负载均衡,支持NAT以及IPIP隧道模式,但LB和RS不能跨子网,IPIP性能次之,通过ipip隧道解决跨网段传输问题,因此能够支持跨子网。而NAT模式没有限制,这也是唯一一种支持端口映射的模式。
但是ipvs只有NAT(也就是DNAT),NAT也俗称三角模式,要求RS和LVS 在一个二层网络,并且LVS是RS的网关,这样回包一定会到网关,网关再次做SNAT,这样client看到SNAT后的src ip是LVS ip而不是RS-ip。默认实现不支持ful-NAT,所以像公有云厂商为了适应公有云场景基本都会定制实现ful-NAT模式的lvs。
我们不难猜想,由于Kubernetes Service需要使用端口映射功能,因此kube-proxy必然只能使用ipvs的NAT模式。
如下Masq表示MASQUERADE(也就是SNAT),跟iptables里面的 MASQUERADE 是一个意思
1 | # ipvsadm -L -n |grep 70.130 -A12 |
为什么clusterIP不能ping通
集群内访问cluster ip(不能ping,只能cluster ip+port)就是在到达网卡之前被内核iptalbes做了dnat/snat, cluster IP是一个虚拟ip,可以针对具体的服务固定下来,这样服务后面的pod可以随便变化。
iptables模式的svc会ping不通clusterIP,可以看如下iptables和route(留意:–reject-with icmp-port-unreachable):
1 | #ping 10.96.229.40 |
如果用ipvs实现的clusterIP是可以ping通的:
- 如果用iptables 来做转发是ping不通的,因为iptables里面这条规则只处理tcp包,reject了icmp
- ipvs实现的clusterIP都能ping通
- ipvs下的clusterIP ping通了也不是转发到pod,ipvs负载均衡只转发tcp协议的包
- ipvs 的clusterIP在本地配置了route路由到回环网卡,这个包是lo网卡回复的
ipvs实现的clusterIP,在本地有添加路由到lo网卡
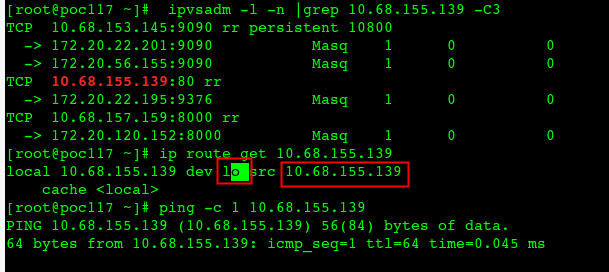
然后在本机抓包(到ipvs后端的pod上抓不到icmp包):
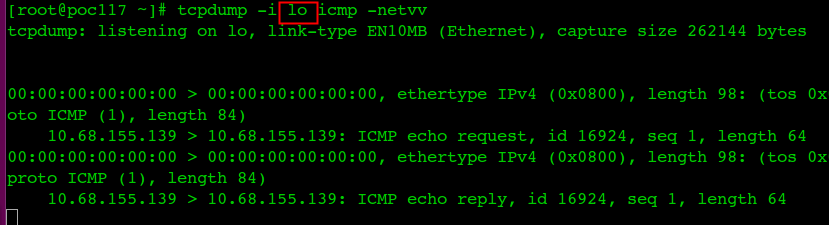
从上面可以看出显然ipvs只会转发tcp包到后端pod,所以icmp包不会通过ipvs转发到pod上,同时在本地回环网卡lo上抓到了进去的icmp包。因为本地添加了一条路由规则,目标clusterIP被指示发到lo网卡上,lo网卡回复了这个ping包,所以通了。
NodePort Service
这种类型的 Service 也能被宿主机和 pod 访问,但与 ClusterIP 不同的是,它还能被 集群外的服务访问。
- External node IP + port in NodePort range to any endpoint (pod), e.g. 10.0.0.1:31000
- Enables access from outside
实现上,kube-apiserver 会从预留的端口范围内分配一个端口给 Service,然后 每个宿主机上的 kube-proxy 都会创建以下规则:
1 | -t nat -A {PREROUTING, OUTPUT} -m conntrack --ctstate NEW -j KUBE-SERVICES |
- 前面几步和 ClusterIP Service 一样;如果没匹配到 ClusterIP 规则,则跳转到
KUBE-NODEPORTSchain。 KUBE-NODEPORTSchain 里做 Service 匹配,但这次只匹配协议类型和目的端口号。- 匹配成功后,转到对应的
KUBE-SVC-chain,后面的过程跟 ClusterIP 是一样的。
NodePort 的一些问题
- 首先endpoint回复不能走node 1给client,因为会被client reset(如果在node1上将src ip替换成node2的ip可能会路由不通)。回复包在 node1上要snat给node2
- 经过snat后endpoint没法拿到client ip(slb之类是通过option带过来)
1 | client |
可以将 Service 的 spec.externalTrafficPolicy 字段设置为 local,这就保证了所有 Pod 通过 Service 收到请求之后,一定可以看到真正的、外部 client 的源地址。
而这个机制的实现原理也非常简单:这时候,一台宿主机上的 iptables 规则,会设置为只将 IP 包转发给运行在这台宿主机上的 Pod。所以这时候,Pod 就可以直接使用源地址将回复包发出,不需要事先进行 SNAT 了。这个流程,如下所示:
1 | client |
当然,这也就意味着如果在一台宿主机上,没有任何一个被代理的 Pod 存在,比如上图中的 node 2,那么你使用 node 2 的 IP 地址访问这个 Service,就是无效的。此时,你的请求会直接被 DROP 掉。
kube-proxy
在 Kubernetes v1.0 版本,代理完全在 userspace 实现。Kubernetes v1.1 版本新增了 iptables 代理模式,但并不是默认的运行模式。从 Kubernetes v1.2 起,默认使用 iptables 代理。在 Kubernetes v1.8.0-beta.0 中,添加了 ipvs 代理模式
kube-proxy相当于service的管理方,业务流量不会走到kube-proxy,业务流量的负载均衡都是由内核层面的iptables或者ipvs来分发。
kube-proxy的三种模式:

一直以来,基于 iptables 的 Service 实现,都是制约 Kubernetes 项目承载更多量级的 Pod 的主要障碍。
ipvs 就是用于解决在大量 Service 时,iptables 规则同步变得不可用的性能问题。与 iptables 比较像的是,ipvs 的实现虽然也基于 netfilter 的钩子函数,但是它却使用哈希表作为底层的数据结构并且工作在内核态,这也就是说 ipvs 在重定向流量和同步代理规则有着更好的性能。
除了能够提升性能之外,ipvs 也提供了多种类型的负载均衡算法,除了最常见的 Round-Robin 之外,还支持最小连接、目标哈希、最小延迟等算法,能够很好地提升负载均衡的效率。
而相比于 iptables,IPVS 在内核中的实现其实也是基于 Netfilter 的 NAT 模式,所以在转发这一层上,理论上 IPVS 并没有显著的性能提升。但是,IPVS 并不需要在宿主机上为每个 Pod 设置 iptables 规则,而是把对这些“规则”的处理放到了内核态,从而极大地降低了维护这些规则的代价。这也正印证了我在前面提到过的,“将重要操作放入内核态”是提高性能的重要手段。
IPVS 模块只负责上述的负载均衡和代理功能。而一个完整的 Service 流程正常工作所需要的包过滤、SNAT 等操作,还是要靠 iptables 来实现。只不过,这些辅助性的 iptables 规则数量有限,也不会随着 Pod 数量的增加而增加。
ipvs 和 iptables 都是基于 Netfilter 实现的。
Kubernetes 中已经使用 ipvs 作为 kube-proxy 的默认代理模式。
1 | /opt/kube/bin/kube-proxy --bind-address=172.26.137.117 --cluster-cidr=172.20.0.0/16 --hostname-override=172.26.137.117 --kubeconfig=/etc/kubernetes/kube-proxy.kubeconfig --logtostderr=true --proxy-mode=ipvs |
port-forward
port-forward后外部也能够像nodePort一样访问到,但是port-forward不适合大流量,一般用于管理端口,启动的时候port-forward会固定转发到一个具体的Pod上,也没有负载均衡的能力。
1 | #在本机监听1080端口,并转发给后端的svc/nginx-ren(总是给发给svc中的一个pod) |
kubectl looks up a Pod from the service information provided on the command line and forwards directly to a Pod rather than forwarding to the ClusterIP/Service port and allowing the cluster to load balance the service like regular service traffic.
The portforward.go Complete function is where kubectl portforward does the first look up for a pod from options via AttachablePodForObjectFn:
The AttachablePodForObjectFn is defined as attachablePodForObject in this interface, then here is the attachablePodForObject function.
To my (inexperienced) Go eyes, it appears the attachablePodForObject is the thing kubectl uses to look up a Pod to from a Service defined on the command line.
Then from there on everything deals with filling in the Pod specific PortForwardOptions (which doesn’t include a service) and is passed to the kubernetes API.
Service 和 DNS 的关系
Service 和 Pod 都会被分配对应的 DNS A 记录(从域名解析 IP 的记录)。
对于 ClusterIP 模式的 Service 来说(比如我们上面的例子),它的 A 记录的格式是:..svc.cluster.local。当你访问这条 A 记录的时候,它解析到的就是该 Service 的 VIP 地址。
而对于指定了 clusterIP=None 的 Headless Service 来说,它的 A 记录的格式也是:..svc.cluster.local。但是,当你访问这条 A 记录的时候,它返回的是所有被代理的 Pod 的 IP 地址的集合。当然,如果你的客户端没办法解析这个集合的话,它可能会只会拿到第一个 Pod 的 IP 地址。
1 | #kubectl get pod -l app=mysql-r -o wide |
不是每个pod都会向DNS注册,只有:
- StatefulSet中的POD会向dns注册,因为他们要保证顺序行
- POD显式指定了hostname和subdomain,说明要靠hostname/subdomain来解析
- Headless Service代理的POD也会注册
Ingress
kube-proxy 只能路由 Kubernetes 集群内部的流量,而我们知道 Kubernetes 集群的 Pod 位于 CNI 创建的外网络中,集群外部是无法直接与其通信的,因此 Kubernetes 中创建了 ingress 这个资源对象,它由位于 Kubernetes 边缘节点(这样的节点可以是很多个也可以是一组)的 Ingress controller 驱动,负责管理南北向流量,Ingress 必须对接各种 Ingress Controller 才能使用,比如 nginx ingress controller、traefik。Ingress 只适用于 HTTP 流量,使用方式也很简单,只能对 service、port、HTTP 路径等有限字段匹配来路由流量,这导致它无法路由如 MySQL、Redis 和各种私有 RPC 等 TCP 流量。要想直接路由南北向的流量,只能使用 Service 的 LoadBalancer 或 NodePort,前者需要云厂商支持,后者需要进行额外的端口管理。有些 Ingress controller 支持暴露 TCP 和 UDP 服务,但是只能使用 Service 来暴露,Ingress 本身是不支持的,例如 nginx ingress controller,服务暴露的端口是通过创建 ConfigMap 的方式来配置的。
Ingress是授权入站连接到达集群服务的规则集合。 你可以给Ingress配置提供外部可访问的URL、负载均衡、SSL、基于名称的虚拟主机等。 用户通过POST Ingress资源到API server的方式来请求ingress。
1 | internet |
可以将 Ingress 配置为服务提供外部可访问的 URL、负载均衡流量、终止 SSL/TLS,以及提供基于名称的虚拟主机等能力。 Ingress 控制器 通常负责通过负载均衡器来实现 Ingress,尽管它也可以配置边缘路由器或其他前端来帮助处理流量。
Ingress 不会公开任意端口或协议。 将 HTTP 和 HTTPS 以外的服务公开到 Internet 时,通常使用 Service.Type=NodePort 或 Service.Type=LoadBalancer 类型的服务。
Ingress 其实不是Service的一个类型,但是它可以作用于多个Service,作为集群内部服务的入口。Ingress 能做许多不同的事,比如根据不同的路由,将请求转发到不同的Service上等等。
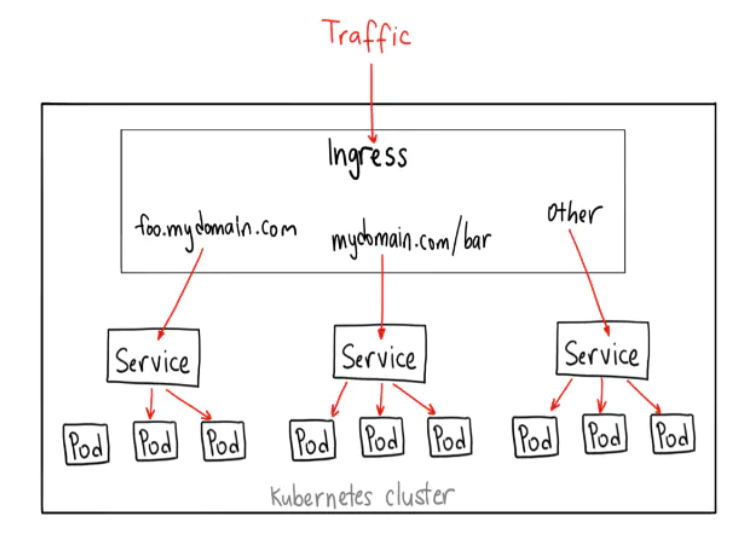
Ingress 对象,其实就是 Kubernetes 项目对“反向代理”的一种抽象。
1 | apiVersion: extensions/v1beta1 |
在实际的使用中,你只需要从社区里选择一个具体的 Ingress Controller,把它部署在 Kubernetes 集群里即可。然后,这个 Ingress Controller 会根据你定义的 Ingress 对象,提供对应的代理能力。
目前,业界常用的各种反向代理项目,比如 Nginx、HAProxy、Envoy、Traefik 等,都已经为 Kubernetes 专门维护了对应的 Ingress Controller。
一个 Ingress Controller 可以根据 Ingress 对象和被代理后端 Service 的变化,来自动进行更新的 Nginx 负载均衡器。
eBPF(extended Berkeley Packet Filter)和网络
eBPF允许程序对内核本身进行编程(即 通过程序动态修改内核的行为。传统方式要么是给内核打补丁,要么是修改内核源码 重新编译)。一句话来概括:编写代码监听内核事件,当事件发生时,BPF 代码就会在内核执行。
eBPF 最早出现在 3.18 内核中,此后原来的 BPF 就被称为 “经典” BPF(classic BPF, cBPF),cBPF 现在基本已经废弃了。很多人知道 cBPF 是因为它是 tcpdump 的包过滤语言。现在,Linux 内核只运行 eBPF,内核会将加载的 cBPF 字节码 透明地转换成 eBPF 再执行。如无特殊说明,本文中所说的 BPF 都是泛指 BPF 技术。
2015年eBPF 添加了一个新 fast path:XDP,XDP 是 eXpress DataPath 的缩写,支持在网卡驱动中运行 eBPF 代码(在软件中最早可以处理包的位置),而无需将包送 到复杂的协议栈进行处理,因此处理代价很小,速度极快。
BPF 当时用于 tcpdump,在内核中尽量前面的位置抓包,它不会 crash 内核;
bcc 是 tracing frontend for eBPF。
内核添加了一个新 socket 类型 AF_XDP。它提供的能力是:在零拷贝( zero-copy)的前提下将包从网卡驱动送到用户空间。
AF_XDP 提供的能力与 DPDK 有点类似,不过:
- DPDK 需要重写网卡驱动,需要额外维护用户空间的驱动代码。
- AF_XDP 在复用内核网卡驱动的情况下,能达到与 DPDK 一样的性能。
而且由于复用了内核基础设施,所有的网络管理工具还都是可以用的,因此非常方便, 而 DPDK 这种 bypass 内核的方案导致绝大大部分现有工具都用不了了。
由于所有这些操作都是发生在 XDP 层的,因此它称为 AF_XDP。插入到这里的 BPF 代码 能直接将包送到 socket。
Facebook 公布了生产环境 XDP+eBPF 使用案例(DDoS & LB)
- 用 XDP/eBPF 重写了原来基于 IPVS 的 L4LB,性能 10x。
- eBPF 经受住了严苛的考验:从 2017 开始,每个进入 facebook.com 的包,都是经过了 XDP & eBPF 处理的。
Cilium 1.6 发布 第一次支持完全干掉基于 iptables 的 kube-proxy,全部功能基于 eBPF。Cilium 1.8 支持基于 XDP 的 Service 负载均衡和 host network policies。
传统的 kube-proxy 处理 Kubernetes Service 时,包在内核中的 转发路径是怎样的?如下图所示:
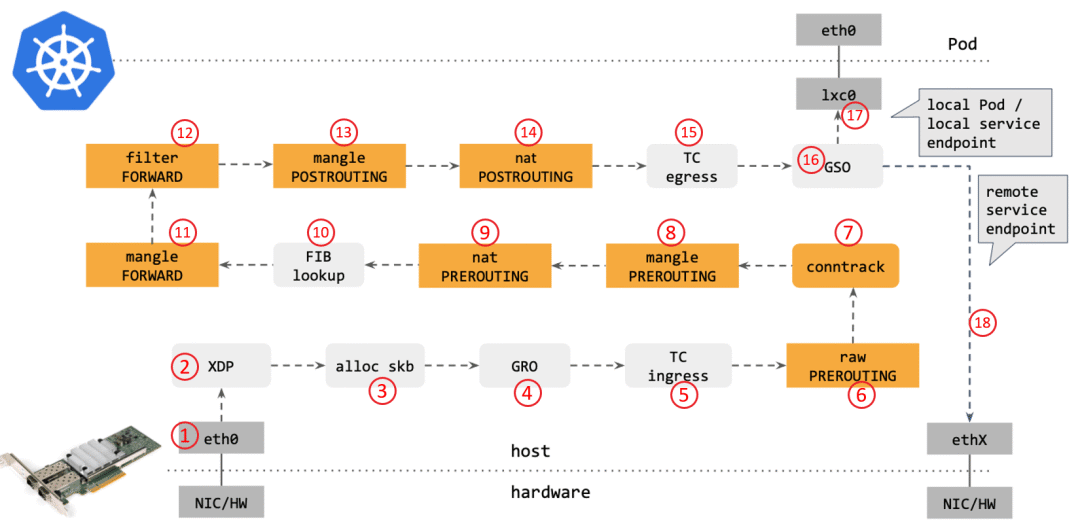
步骤:
- 网卡收到一个包(通过 DMA 放到 ring-buffer)。
- 包经过 XDP hook 点。
- 内核给包分配内存,此时才有了大家熟悉的 skb(包的内核结构体表示),然后 送到内核协议栈。
- 包经过 GRO 处理,对分片包进行重组。
- 包进入 tc(traffic control)的 ingress hook。接下来,所有橙色的框都是 Netfilter 处理点。
- Netfilter:在 PREROUTING hook 点处理 raw table 里的 iptables 规则。
- 包经过内核的连接跟踪(conntrack)模块。
- Netfilter:在 PREROUTING hook 点处理 mangle table 的 iptables 规则。
- Netfilter:在 PREROUTING hook 点处理 nat table 的 iptables 规则。
- 进行路由判断(FIB:Forwarding Information Base,路由条目的内核表示,译者注) 。接下来又是四个 Netfilter 处理点。
- Netfilter:在 FORWARD hook 点处理 mangle table 里的iptables 规则。
- Netfilter:在 FORWARD hook 点处理 filter table 里的iptables 规则。
- Netfilter:在 POSTROUTING hook 点处理 mangle table 里的iptables 规则。
- Netfilter:在 POSTROUTING hook 点处理 nat table 里的iptables 规则。
- 包到达 TC egress hook 点,会进行出方向(egress)的判断,例如判断这个包是到本 地设备,还是到主机外。
- 对大包进行分片。根据 step 15 判断的结果,这个包接下来可能会:发送到一个本机 veth 设备,或者一个本机 service endpoint, 或者,如果目的 IP 是主机外,就通过网卡发出去。
Cilium 如何处理POD之间的流量(东西向流量)
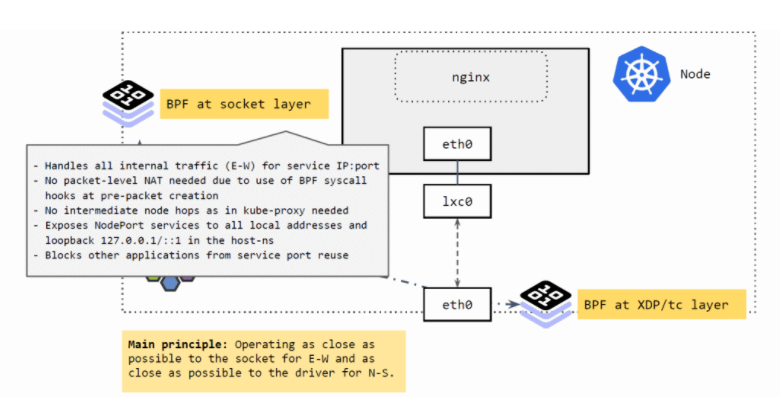
如上图所示,Socket 层的 BPF 程序主要处理 Cilium 节点的东西向流量(E-W)。
- 将 Service 的 IP:Port 映射到具体的 backend pods,并做负载均衡。
- 当应用发起 connect、sendmsg、recvmsg 等请求(系统调用)时,拦截这些请求, 并根据请求的IP:Port 映射到后端 pod,直接发送过去。反向进行相反的变换。
这里实现的好处:性能更高。
- 不需要包级别(packet leve)的地址转换(NAT)。在系统调用时,还没有创建包,因此性能更高。
- 省去了 kube-proxy 路径中的很多中间节点(intermediate node hops) 可以看出,应用对这种拦截和重定向是无感知的(符合 Kubernetes Service 的设计)。
Cilium处理外部流量(南北向流量)
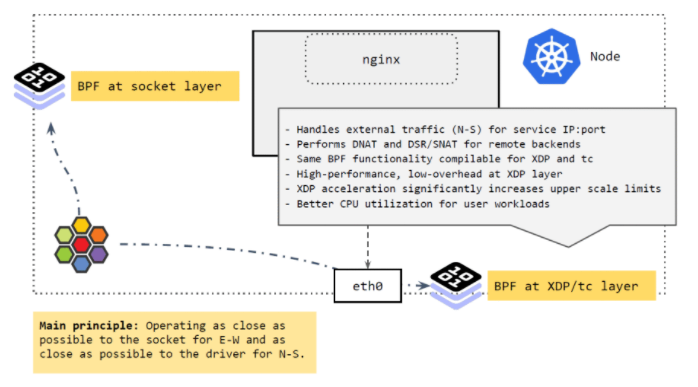
集群外来的流量到达 node 时,由 XDP 和 tc 层的 BPF 程序进行处理, 它们做的事情与 socket 层的差不多,将 Service 的 IP:Port 映射到后端的 PodIP:Port,如果 backend pod 不在本 node,就通过网络再发出去。发出去的流程我们 在前面 Cilium eBPF 包转发路径 讲过了。
这里 BPF 做的事情:执行 DNAT。这个功能可以在 XDP 层做,也可以在 TC 层做,但 在XDP 层代价更小,性能也更高。
总结起来,Cilium的核心理念就是:
- 将东西向流量放在离 socket 层尽量近的地方做。
- 将南北向流量放在离驱动(XDP 和 tc)层尽量近的地方做。
性能比较
测试环境:两台物理节点,一个发包,一个收包,收到的包做 Service loadbalancing 转发给后端 Pods。
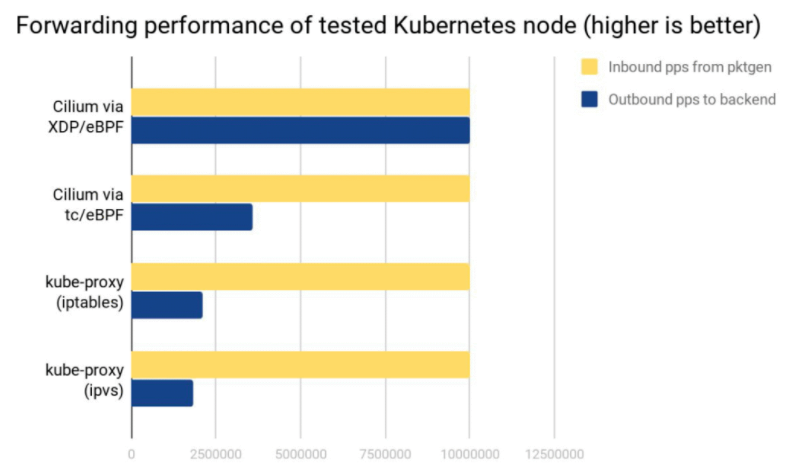
可以看出:
- Cilium XDP eBPF 模式能处理接收到的全部 10Mpps(packets per second)。
- Cilium tc eBPF 模式能处理 3.5Mpps。
- kube-proxy iptables 只能处理 2.3Mpps,因为它的 hook 点在收发包路径上更后面的位置。
- kube-proxy ipvs 模式这里表现更差,它相比 iptables 的优势要在 backend 数量很多的时候才能体现出来。
cpu:
- XDP 性能最好,是因为 XDP BPF 在驱动层执行,不需要将包 push 到内核协议栈。
- kube-proxy 不管是 iptables 还是 ipvs 模式,都在处理软中断(softirq)上消耗了大量 CPU。
利用 ebpf sockmap/redirection 提升 socket 性能
通过bpf监听socket来拦截所有sendmsg事件,如果是发送到本地另一个socket那么bpf就绕过TCP/IP协议栈,直接将msg送给对方socket。依赖用cgroups来指定监听的sockets事件

实现这个功能依赖两个东西:
sockmap:这是一个存储 socket 信息的映射表。作用:
- 一段 BPF 程序监听所有的内核 socket 事件,并将新建的 socket 记录到这个 map;
- 另一段 BPF 程序拦截所有
sendmsg系统调用,然后去 map 里查找 socket 对端,之后 调用 BPF 函数绕过 TCP/IP 协议栈,直接将数据发送到对端的 socket queue。
cgroups:绑定cgroup下的进程,从而将这些进程下的所有 socket 加入到sockmap。
参考资料
https://imroc.cc/blog/2019/08/12/troubleshooting-with-kubernetes-network Kubernetes 网络疑难杂症排查方法
https://blog.csdn.net/qq_36183935/article/details/90734936 kube-proxy ipvs模式详解
http://arthurchiao.art/blog/ebpf-and-k8s-zh/ 大规模微服务利器:eBPF 与 Kubernetes
http://arthurchiao.art/blog/cilium-life-of-a-packet-pod-to-service-zh/ Life of a Packet in Cilium:实地探索 Pod-to-Service 转发路径及 BPF 处理逻辑
http://arthurchiao.art/blog/understanding-ebpf-datapath-in-cilium-zh/ 深入理解 Cilium 的 eBPF 收发包路径(datapath)(KubeCon, 2019)
利用 ebpf sockmap/redirection 提升 socket 性能
利用 eBPF 支撑大规模 K8s Service (LPC, 2019)